
Finding Code
There's an art to quickly finding code in unfamiliar territory

Last week, a friend of mine asked me if I could help on a project of his. It was built over two years ago. It uses NextJS for the frontend, and various AWS technologies on the backend.
He tasked me with a simple task of fixing a small bug, and told me to “spend some time looking around the codebase.” At this moment, I immediately thought of Mike, and how this could be a useful learning opportunity.
When I’m entering a new codebase, all of the things I do to figure out the code structure feel second nature to me.
One of the most crucial things I’ve learned, is finding code from the user interface, without needing to understand the structure from the original author.
This might sound a little crazy, especially if you’re new to programming, but I’ve learned over the years, even the most messy, and poorly thought out systems, have some easy tricks to find the underlying code! I’ll share three ways with you today.
If you have a tip of your own, please consider sharing it with us!
Copying Text on Screen
Here’s a random screenshot from Stripe’s api documentation:

Imagine it’s day 1 on the job. We haven’t even looked at the codebase for the documentation source code. A pretty simple idea would be copying Set up the CLI and pasting this into our code editor. For reference, I use VS Code.
If we do this, chances are you will find only a few references. No other pages talk about setting up the CLI. You should very quickly be taken to the exact location of the code that powers this Stripe CLI blurb in the docs!
This works great when you are able to search for text in the application that is stored directly in the frontend. What if the page you are working on only has text received from an api?
Searching for the Request
Let’s look at another production application. This is the Vercel dashboard page that shows the domains you have linked to your account:

If you open up “Inspect Element” in your browser and then navigate to the network tab, look for what requests take place on this page. You will find:

And the response payload:
This gives us multiple things we can search in a messy codebase to find where this page lives inside the code!
We can search the codebase for /domains and see if we find any exact matches. I would expect this to take us directly to the network request layer.
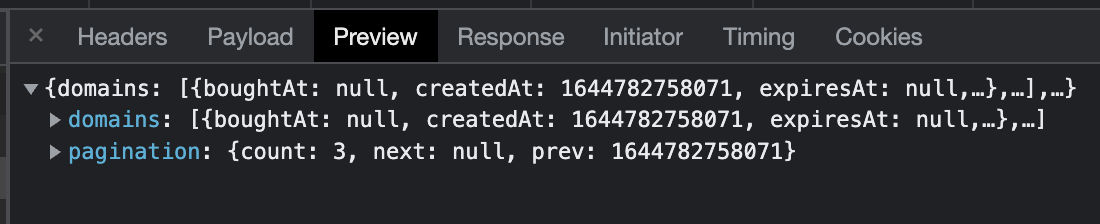
What if we want to find the component that renders the domains on the page? We can look inside the response payload, and search for a unique key that we believe is unique to this request.
Here’s what I mean:
You’ll notice in the photo above, there is a boughtAt parameter inside of the domains array. This key is hopefully used rarely in the application. After all, I wouldn’t expect many things to include that parameter. So let’s search the codebase for boughtAt and see how many results we are left with.
If there’s too many, we can try another key. I find this can happen really quick, this entire section and multiple attempts could take you 30s or less to find the area of the code you are looking for.
HTML / CSS Markup
This can be very useful depending on the type of CSS framework or html markup used when inspecting an element. Here’s the html content of a piece of the page I need to work on in a real project:

Since this project uses tailwind, it’s a safe bet that we can search for a portion of these classes. In this case I will copy mb-5 grid grid-cols-2 bg-white from the start of this class list….
Viola!

Only two references in this giant codebase! In a matter of a few seconds with this tip, we are able to jump right into the code.
This won’t always work, as there could be code that generates all the outputted classes. This is why I will copy and paste a portion of Tailwind classes when doing this trick. Enough copied that it’s somewhat unique, and not too many that I end up getting no matches.
Bonus: The Current Page URL
This one is the most obvious, and very useful for most structured applications. Many frameworks such as NextJS or Remix will force you to have one TS file as an entry point to a route. If we need to work on a page with a url of /auth/user, we should be able to go to something like pages/auth/user.ts, no searching required!
Even with this being said, I have found that it can be faster to quickly search for the html, classname, or network request info if you have a hunch as to how the codebase is setup and how the developer did things.
Summary
Every codebase is different. After you see a hundred of them, you will start to have very good instincts for many ways to quickly pull up the code that generates any section of a site.